No One Can Compare LLMs
Recently at work I received access to a Claude account (that I stopped using because found it *meh*). It works well, but since I prefer ChatGPT I asked for a swap. When I did so, my manager seemed surprised - in his opinion, Claude is simply better.
That got me thinking about what “better” actually means.
I generally give people the benefit of the doubt, so let’s assume he’s right. Claude is better for him. So why is ChatGPT better for me?
And I figured: comparing LLMs objectively is almost impossible because the interaction is deeply personalized.
When you interact with a LLM, you’re interacting with it much like you would with another human (magic of chat interface). And we all communicate differently - we have our habits, shortcuts, assumptions, biases. Two people rarely write the same prompt for the same task.
The growing use of persistent memory makes this even more visible. Same prompt can produce different results depending on what the model has learned about you over months of interaction.
Thus: there is no objectively better model. There is only a model that aligns better with the way you work.
My Prompting Style
My prompting style is sloppy.
For example, while preparing the rik 0.4.0 release:
Check JJ repository from 0.3.0. I would like to prepare for the new release so check what was changed. Propose modifications to README. Modify changelog. Bump version. Etc.
Or when troubleshooting Kakoune:
I don’t see cursor when in insert mode, fix it.
I don’t care about grammar, capitalization, typos. I frequently steer the task while working. I’d rather fix the output afterward than spend time on the perfect prompt.
Surprisingly though, ChatGPT often gets what I mean in a single shot. Claude is like an assistant I’d fire after a week.
But: De gustibus non est disputandum1.
Work Style
Another example: When I’m working on rik, I often create a temporary file in the repository, usually something like test.txt, to check how markers behave in a file. (by the way, check out rik if you haven’t - I’m quite proud with how it progresses).
Claude and ChatGPT react to the file in completely different ways.
Claude finds the new file and immediately decides it’s an important part of the project. It wants to lint it, add tests for it, make sure it’s tracked if it isn’t already, format it, in short - make it consistent with the rest of the directory contents. Nothing I wanted or asked for: frustrating.
GPT, on the other hand, reacts in a way that I find quite amusing. It notices that the file is called test.txt and the recent timestamp and infers that it’s probably something I created ad-hoc and the file shouldn’t be touched at all.

Again and again, this is my approach. Others might keep temporary files in a separate directory, or solve the problem completely differently.
This issue is totally personal one, and it only becomes visible because of how I work.
That doesn’t mean Claude is worse. Many say it’s better, and I believe them - with the one caveat: it’s not objectively better - it’s better for them.
Code
Working on rik shown me another interesting pattern; people constantly argue online about token usage.
Some claim Claude burns through context windows incredibly quickly. Others say exactly the opposite and complain about GPT. And everybody are right ;-)
The missing “variable” is the code they’re feeding into the model.
Different repositories have different structures, naming conventions, and architectural styles. That changes how good an agent is when navigating it.
Take file size.
I’ve seen agent-generated projects containing files with tens of thousands of lines of code.
I’m a software engineer who is allergic to that. Once a file grows beyond roughly a thousand lines, I start looking for ways to split it.
Maybe some developers working in agent-first workflows don’t care whether a file contains one thousand lines or hundred thousands as long as it work.
Then consistency.
Humans aren’t perfectly consistent. I can call something r, res, result, or tmp_result - all within the same Rust code.
LLMs are much more consistent than I am - they even often rename variables to keep naming uniform.
Imagine an agent searching for result. In my file agent might find three occurrences. In a highly uniform agent-generated repository it may find 1,500.
If those matches span a 100,000-line file, the model suddenly has to ingest a truckload of context. Multiply that by dozens of files and welcome warmly Mr. Session Limit joining in.

Me - I have many small files. Is it why Claude seems to consume context quickly in my code? Maybe, or maybe not. 418, I don’t know.
Same conclusion.
The problem isn’t at all about whether Claude or ChatGPT is better. The problem is about how efficient they are in my environment.
WYGIWIL (pronounced “Wig Evil”)
What You Get Is What It Learned2.
LLMs retrieve compressed knowledge from an enormous latent space.
The closer your prompt matches patterns that appeared during training, the better the result tends to be. Take language for example.
If a model was trained on Chinese material, asking about problems in Chinese will likely produce better answers than asking in English (even though results will be in Chinese - translation breaks no sweat for LLMs).
Another interesting example is politeness:
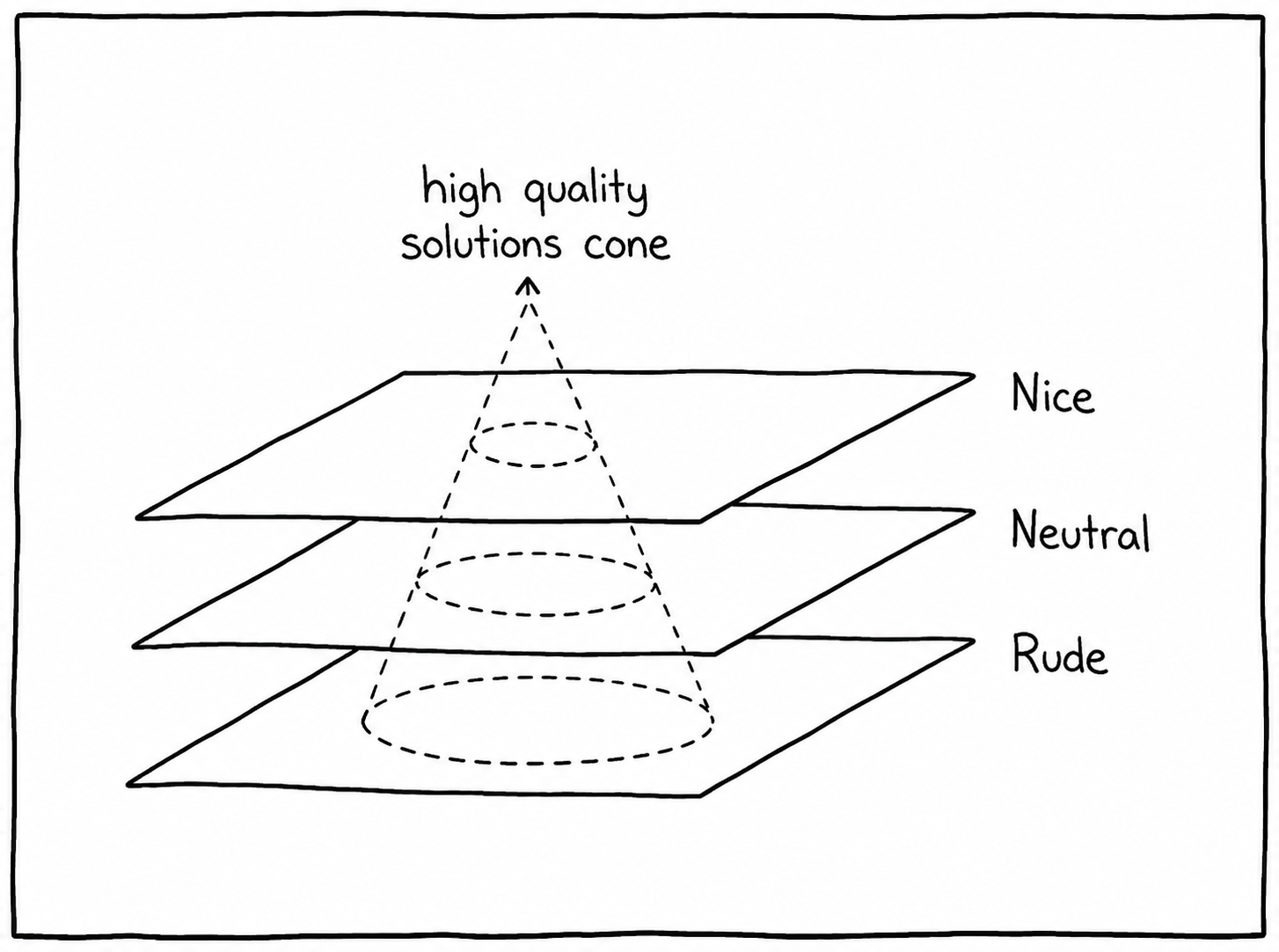
Some research suggests that overly polite prompts can perform worse than direct or even rude ones. I have simple theory for that:
The internet contains endless examples of harsh code reviews producing improvements. I believe strong, even brutal, criticism has higher chance of being a catalyst for a change.
Whether that’s true or not, it’s definitely yet another parameter affecting output.
Apples and Oranges
Why benchmark discussions often are polarized? Not the benchmarks fault. They simply measure for a specific, lab crafted, environment.
In my mind it’s like grabbing a cat, an ostrich and a dolphin and ask them to compete in 400m race to figure out which animal is the best.
In above analogy it’s ridiculous, because humans usually understand what qualities a cat, an ostrich or a dolphin might have. No one expect a dolphin to even finish a race on land.
Software engineering is so difficult and complex discipline that we haven’t even found quantificators for code style beyond linters and counters. No one says “my codebase is best handled by an Engineer who likes to eat bananas”. That’d be bananas! There’s absolutely no way to estimate effectiveness of an engineer based on their qualities (see countless essays and research on inadequate hiring metrics in software).
Imagine we do, though. We could ask then: how model aligns with big files, short files, many variables, uniform variables, high branching, low branching, wide impact scopes, low impact scopes etc.
My point is: in a benchmark 90% model might dominate over 40%, but given:
- your prompting style
- your code/context
…winner might be 10% effective and loser 90% effective. You can’t tell.
I benchmarked a bear, an eagle, and a guinea pig. Unsurprisingly guinea pig got 78.3%, bear 43.2%. Eagle performed much lower than expected with only 41%.
QUICK: everybody get a guinea pig!
Better Metrics
I think that the next generation of benchmarks shouldn’t ask “How well this model solves that problem” but instead they should ask “how compatible this model is with you”.
i.e. instead of giving 100 tasks and see how many they complete, give it 5 for 20 context styles and give its profile
Then you could show your codebase and get a profile of your environment. And show your prompts to get a profile on it too.
Only then you get a score: an OkCupid-like style for your LLM needs!

The Value Gained
Today Anthropic’s Fable 5 is the latest craze.
As usual, opinions are split. Some people say it’s incredible and cheaper due concise outputs.
Others complain that a single prompt exhausted their limits without even finishing a task. I guess theses expereinces are true on the both sides.
For me the more important than the benchmark scores is usage friction. I’ve used Claude extensively. I’ve used Chinese providers thanks to a friend who gave me generous access. I’ve tested tens of various models through OpenRouter. Recently I spent some time with ChatGPT Codex.
ChatGPT aligns with my style the best. It’s less frustrating, it doesn’t try to solve problems I never asked it to solve, I don’t argue with it: It’s a good bot.
But is it five times better than the non-SOTA models? I’m not sure if I’d call it twice as good (though it might be close): for my style and for my code.
What I want to say: there’s no way to have an universal benchmark or opinion. It’s fun for argument, but not valuable for a selection.
The only way to evaluate LLM is:
- Connect it to your tools
- Communicate with it how you like
- Run it in your code
- …and decide if you like it or not.
Only then will you discover which model is actually the best. For you.

Przemysław Alexander Kamiński
vel xlii vel exlee
Powered by hugo and hugo-theme-nostyleplease.